
본 글은 기록 저장을 위해 제 회사 위키 글을 각색해서 옮겨온 글 입니다.
Introduction
2023년 8월 초 즈음, 특정 패턴의 장애가 본격적으로 우리 팀을 괴롭히기 시작한다.

Airflow 배치가 알 수 없는 이유로 실패하여 로그를 확인해보면, 항상 WorkerLostError 라는 에러를 확인 할 수 있었다. 이전부터 간헐적으로 계속 있었던 이슈였지만 8월 부터 꽤 자주 발생하기 시작했다. 그래서 우선은 관련해서 AWS 측에 Case Open 하였다. 돌아온 답변은 다음과 같다.
MWAA Service 팀에서는, 다음 위와 같은 해당 메시지는 Auto-scaling과 관련된 메시지가 아니며, celery에서 child 프로세스 중 하나가 일정 시간 동안 상태를 업데이트하지 않을 때 나타나는 메시지로, 이것은 실질적인 스케일링 다운을 나타내는 것이 아니라고 하였습니다. ECS Log를 확인 하여 보았음에도, 해당 시간에 자동 스케일링이 발생하지 않았음을 확인하였으며, 이 메시지는 일반적으로 분산 프로세스나 작업을 처리하는 동안에 발생하는 일시적인 메시지라고 확인받았습니다. 따라서, 해당 메시지는 Auto-scaling과 관련되지 않은 Celery로 부터 오는 프로세스 메시지로 MWAA 의 Auto-scaling과 직접적인 관련이 없음을 안내드립니다. 만일 해당 에러와 함께 지속적인 작업 실패가 있지 않다면, 해당 에러 메시지는 걱정하지 않으셔도 된다고 안내 받았습니다.
이와 관련해서는 작업이 실패했을 경우 재시도와 관련된 적절한 구성을 구현하시길 추천드리며, 해당 메시지와 관련하여 크게 걱정하지 않으셔도 될 것으로 보입니다.[1]
조금이나마 도움이 되셨기를 바라며, 이와 관련하여 추가 문의사항이나 요청사항이 있으시다면 언제든지 회신 부탁드립니다.
오늘도 좋은하루 보내시기를 바라겠습니다.
안녕하세요. 고객님. 다시 회신주셔서 감사합니다.
고객님의 추가 문의와 관련하여 다음 아래와 같이 답변드립니다.
일반적으로 Celery는 Worker로 부터 일정 간격으로 상태를 업데이트 받고, 진행 상황등을 보고받아 Worker process를 모니터링 하게 됩니다. 이를 통해 Celery는 워커의 활성 상태를 확인하고 문제가 발생한 경우 조치를 취하게 되는데요, 만일 Worker로 부터 해당 보고가 일정 시간 동안 오지 않을 경우에는, 비정상적인 상황으로 간주하고 해당 Worker를 재시작 하거나, 다른 워커로 이전하거나 등의 조치를 취할 수 있습니다. 일반적으로 Worker가 상태를 보고할 수 없는 상황은 다음 아래와 같습니다.
1. 리소스가 부족한 현상
Worker가 충분한 Memory 나 CPU 를 확보하지 못하여 작업을 수행하지 못하는 경우가 가장 많이 발생하는 원인입니다. 따라서, 고객님의 해당 현상이 발생한 시간대의 CPU Utilization, Memory Utilization도 확인하여 보고, 해당 MWAA Environment Pool Metrics도 확인하여 보았지만, 리소스는 충분하였음을 확인하여 해당 원인으로 발생한 이슈는 아닐것으롭 보입니다.
2. 네트워크 문제
Worker와 Celery 간의 통신 문제가 발생하면 일시적으로 상태 보고를 전달 받지 못할 수 있습니다. 이는 일시적인 네트워크 문제나, 서버 장애 또는 시스템 이슈나 신호 문제로 통신이 지연되는 현상 속에서 발생할 수 있는 일시적인 원인입니다.
3. 작업 코드 수행 중 예외나 오류 발생
Worker가 해당 작업 코드에 의해 작업 수행 중, 예외나 오류가 발생할 경우 프로세스를 예기치 않게 중단하거나 비정상적으로 'WorkerLostError' 와 함께 종료될 수 있습니다. 또는, Worker가 해당 작업을 수행할 때 너무 오랜 시간동안 작업을 처리하게 되어 정해진 시간동안에 상태를 보고할 수 없을 수 있습니다.
위와 같은 이유로 해당 현상이 발생하게 되는 경우, task 가 자동으로 retry되는 현상이 있다고 하셨는데요. 만일, Celery에서 작업이 실패하면 지정된 조건에 따라 작업이 다시 실행될 수 있도록 설정이 되어 있는 것 같습니다. 참고문헌[1]에 따라 고객님의 retry 값을 확인하여 주시기 바랍니다. 만일 retry 값이 지정되어 있으시다면, 해당 값을 0으로 설정하셔서 task가 실패하더라도 Celery는 작업을 재시도하지 않도록 해당 현상을 방지하실 수 있습니다. [2] 또한, 고객님의 명확한 원인을 파악하기 위하여 MWAA 서비스팀에 더 명확한 원인을 확인할 수 있는지 추가 문의를 남겨두었습니다. MWAA 서비스팀에서 업데이트 오는대로 고객님께 안내드리도록 하겠습니다.
조금이나마 도움이 되셨기를 바라며, 이와 관련하여 추가 문의사항이나 요청사항이 있으시다면 언제든지 회신 부탁드립니다.
오늘도 좋은하루 보내시기를 바라겠습니다.
간단하게 요약하자면,
- MWAA (Airflow) 상의 이슈는 아니다
- Celery 와 연관된 로그이며, 크게 걱정하지 않아도 된다
- 해결책으로는, Retry 에 대한 적절한 조치를 취하던가 아니면 Retry 를 꺼라
하지만 AWS 측에서 제시해준 1, 2, 3 케이스 모두 우리와 연관이 없는 상황으로 확인이 되었다. 제시해준 해결책 또한 근본적인 해결이 아닌 다소 터무니 없는 미봉책으로 보였다. 보다 근본적인 원인과 해결책을 알아내기 위해, 업무 외 시간을 이용해 직접 해당 에러에 대해 파헤쳐 보기로 했다.
Body
상황 분석
하지만 Celery 때문이라는 것 외에는 어떠한 힌트도 없었다. 추가적인 인사이트를 얻기 위해 MWAA Worker 로그를 좀 더 살펴볼 필요가 있었다. Worker Log 를 보면 로그가 단순히 시간 순서대로 나열되어 있다. 하지만 시간 기준이 아닌 task 기준으로 한 번 재배열 해보면 뭔가 유의미한 패턴이 발견 될 수 있지 않을까? 다음은 재배열 했던 로그들의 샘플이다.
# Task: 95b33176-9d20-4f17-8fcc-223397f81b6b
[2023-08-16 17:00:05,276: INFO/MainProcess] Task airflow.executors.celery_executor.execute_command[95b33176-9d20-4f17-8fcc-223397f81b6b] received
[2023-08-16 17:00:05,276: INFO/MainProcess] Scaling up 1 processes.
[2023-08-16 17:00:05,613: INFO/ForkPoolWorker-119] [95b33176-9d20-4f17-8fcc-223397f81b6b] Executing command in Celery: ['airflow', 'tasks', 'run', 'task_name_1', 'something_task_1', 'scheduled__2023-08-15T17:00:00+00:00', '--local', '--subdir', 'DAGS_FOLDER/task_name_1.dag.py']
[2023-08-16 17:08:03,258: INFO/ForkPoolWorker-119] Task airflow.executors.celery_executor.execute_command[95b33176-9d20-4f17-8fcc-223397f81b6b] succeeded in 477.7789185599977s: None
# Task: cfbdf340-5ec7-49f0-aba9-b57763a34757
[2023-09-21 00:30:01,656: INFO/MainProcess] Task airflow.executors.celery_executor.execute_command[cfbdf340-5ec7-49f0-aba9-b57763a34757] received
[2023-09-21 00:30:01,657: INFO/MainProcess] Scaling up 1 processes.
[2023-09-21 00:30:22,429: INFO/ForkPoolWorker-8341] [cfbdf340-5ec7-49f0-aba9-b57763a34757] Executing command in Celery: ['airflow', 'tasks', 'run', 'task_name_2', 'something_task_2', 'scheduled__2023-09-20T23:30:00+00:00', '--local', '--subdir', 'DAGS_FOLDER/task_name_2.dag.py']
[2023-09-21 00:30:32,391: INFO/MainProcess] Scaling down 1 processes.
[2023-09-21 00:30:42,472: ERROR/MainProcess] Task handler raised error: WorkerLostError('Worker exited prematurely: exitcode 15 Job: 6917.')
이렇게 노가다 정리해보니 이전에는 보이지 않던 다음과 같은 사실들이 새롭게 눈에 들어왔다.
- 패턴이 확실히 보인다: Task Receive → Scale Up (if required) → Execute Command in Celery → Task succeeded in xxxs → Scale Down (if required)
- WorkerLostError 발생 전에는 항상 Scaling down X processes 라는 로그가 찍혀있다
- WorkerLostError 발생 후에는 특정 task 의 Task succeedded in xxxs 메세지가 찍히지 않는다. 그리고 그 특정 Task 는 에러 알람이 왔던 task와 일치한다
정황상 Auto-Scaling 기능으로 인한 에러인 것으로 짐작이 된다. 그리고 찾아보니 Celery에 auto-scale 기능이 있었다. 이제 AWS 측 답변이 조금 더 명확하게 이해가 간다. AWS 측에서는 계속해서 auto-scale 때문이 아니라고 했다. 하지만, 그들이 말한 auto-scale은 Airflow 의 auto-scale (= worker node auto-scale) 을 이야기 한 것이었고, 문제가 되는 auto-sacle 은 Celery 의 auto-scale (= Celery worker auto-scale) 인 것. 용어가 같으니 혼란이 왔던 것이다 (솔직히 AWS 측 답변이 다소 모호하게 왔다는 생각이 든다;;).
Figure 1은 Airflow 에서 Celery Executor 를 사용하면 Task Execution 이 어떻게 흘러가는지를 보여주는 Sequence diagram 이다. 여기서 오른쪽 Worker 음영 부분을 주목해보자. 해당 영역은 Worker Node (Airflow Worker) 이다. 그리고 내부적으로는 WorkerProcess (Celery Worker) 에서 바로 task 를 처리하지 않고 (4 Send task) WorkerChildProcess 에게 한 번 더 위임하여 Task 를 처리 (5 Start process) 하는 것을 확인 할 수 있다. 아마 이 부분에서 auto-scale 기능이 들어가는 것으로 유추해 볼 수 있다.
추가로 관련해서 구글링을 해보니 연관 이슈들을 찾을 수 있었다. 이를 요약해 보면 다음과 같다:
- WorkerLostError - Celery Auto-scale 관련 known issues
- Airflow 측에서의 해당 이슈 대응 개발:
위 글 들을 읽어보면, Scale-down 대상인 Celery WorkerChildProcess 에 Task 가 할당되면서 타이밍 이슈로 WorkerLostError가 나는 것으로 보인다. 보다 정확한 메커니즘을 파악하기 위해 소스 코드를 분석해보기로 했다.
Celery 소스 코드 분석
이 부분은 내용이 길기 때문에, 관심 있으신 분만 읽는 것을 추천드립니다. 시간이 없으시다면, 바로 Conclusion 파트로 넘어가시는 것을 추천드립니다.
- MWAA version: v2.4.3 / celery provider version: v3.0.0 / celery verison: >=5.2.3,<6
Celery v5.2.3 기준 Worker 와 autoscale 에 관련된 소스 코드 위주로 살펴보자. 용어 남용 및 혼란을 방지하기 위해 Figure 1 의 Sequence Diagram 에 나온 용어 WorkerProcess, WorkerChildProcess 를 사용하고자 한다.
Worker (WorkerProcess)
# celery/worker/worker.py
class WorkController: <-- WorkerProcess 구현체 (celery/apps/worker.py 의 Worker)의 상위 클래스
"""Unmanaged worker instance."""
...
class Blueprint(bootsteps.Blueprint):
"""Worker bootstep blueprint."""
name = 'Worker'
default_steps = {
'celery.worker.components:Hub',
'celery.worker.components:Pool',
'celery.worker.components:Beat',
'celery.worker.components:Timer',
'celery.worker.components:StateDB',
'celery.worker.components:Consumer',
'celery.worker.autoscale:WorkerComponent',
}
Celery Worker (WorkerProcess)의 상위 클래스 WorkController. Blueprint 라는 내부 클래스를 보면, worker와 연관된 bootstep 들을 확인할 수 있다. Parent Object (i.e. Worker) 가 initialize 될 때, 함께 initialize 되어야하는 object 들 (i.e. Worker가 의존하는 객체들) 을 bootstep 으로 명시해준다. 여기보면 default_steps 의 마지막 줄에 celery.worker.autoscale:WorkerComponent 이 눈에 띈다. Auto-scale 과 관련된 step 인 것 같다.
Auto-scale (Pool & WorkerChildProcess)
# celery/worker/autoscale.py
class WorkerComponent(bootsteps.StartStopStep):
"""Bootstep that starts the autoscaler thread/timer in the worker."""
...
def create(self, w):
scaler = w.autoscaler = self.instantiate(
w.autoscaler_cls,
w.pool, w.max_concurrency, w.min_concurrency,
worker=w, mutex=DummyLock() if w.use_eventloop else None,
)
return scaler if not w.use_eventloop else None
WorkerProcess 의 auto-sacle 관련 bootstep 중 하나 였던 WorkerComponent. auto-scale 로직은 어떻게 이루어질까? autoscaler의 실 구현체를 살펴보자.
# celery/worker/autoscale.py
class Autoscaler(bgThread):
"""Background thread to autoscale pool workers."""
...
def maybe_scale(self, req=None):
if self._maybe_scale(req): <-- _maybe_scale 을 통해 scaling 진행 하고 scaling (up/down)이 되었다면 True, 아니면 False 를 반환
self.pool.maintain_pool() <-- 만약 scale 되었다면 pool 도 이에 맞춰서 maintain 해준다
def _maybe_scale(self, req=None):
procs = self.processes
cur = min(self.qty, self.max_concurrency)
if cur > procs:
self.scale_up(cur - procs)
return True
cur = max(self.qty, self.min_concurrency)
if cur < procs:
self.scale_down(procs - cur)
return True
위 내용들을 종합해 보면 다음과 같다
- WorkerComponent 에서 Worker (WorkerProcess) 에게 autoscaler를 instantiate 해준다
- autoscaler 는 maybe_scale 메서드를 통해서 pool을 grow 하거나 shrink 한다
여기서 pool 이란? 바로 WorkerChildProcess 에 대한 pool (Task Pool) 이다. Airflow 에서는 Default 로 Prefork pool 을 사용한다.
# celery/concurrency/prefork.py
class TaskPool(BasePool): <-- Autoscaler 와 Worker 의 컴포넌트로 들어가는 pool 클래스 (Proxy)
"""Multiprocessing Pool implementation."""
Pool = AsynPool
BlockingPool = BlockingPool
uses_semaphore = True
write_stats = None
def on_start(self):
forking_enable(self.forking_enable)
Pool = (self.BlockingPool if self.options.get('threads', True)
else self.Pool) <-- Pool 이 default다 (threads 는 False로 들어온다)
proc_alive_timeout = (
self.app.conf.worker_proc_alive_timeout if self.app
else None
)
P = self._pool = Pool(processes=self.limit,
initializer=process_initializer,
on_process_exit=process_destructor,
enable_timeouts=True,
synack=False,
proc_alive_timeout=proc_alive_timeout,
**self.options) <-- 실제 Pool 동작을 담당할 pool 컴포넌트 (필드)
# Create proxy methods
self.on_apply = P.apply_async
self.maintain_pool = P.maintain_pool
self.terminate_job = P.terminate_job
self.grow = P.grow
self.shrink = P.shrink
self.flush = getattr(P, 'flush', None) # FIXME add to billiard# celery/concurrency/asynpool.py
class Worker(_pool.Worker):
"""Pool worker process."""
...
class AsynPool(_pool.Pool): <-- Pool
"""AsyncIO Pool (no threads)."""# billiard/pool.py
class Worker:
...
class Pool: <-- BlockingPool
'''
Class which supports an async version of applying functions to arguments.
'''
위 코드 블록 내용들을 종합하여 도식화 해보면 다음과 같다.

즉, Worker (= WorkerProcess)가 Child Worker를 담는 Pool (= Task Pool = WorkerChildProcesses) 을 컴포넌트로 들고 있으면서 auto-scale 하는 구조. 그렇다면 언제 scaling 을 시도할까?
# celery/worker/autoscale.py
AUTOSCALE_KEEPALIVE = float(os.environ.get('AUTOSCALE_KEEPALIVE', 30))
...
class WorkerComponent(bootsteps.StartStopStep):
"""Bootstep that starts the autoscaler thread/timer in the worker."""
...
def register_with_event_loop(self, w, hub):
w.consumer.on_task_message.add(w.autoscaler.maybe_scale) <-- task message 를 receive 할 경우 autoscaler.maybe_scale 이 호출되도록 consumer 측에 callback add
hub.call_repeatedly(
w.autoscaler.keepalive, w.autoscaler.maybe_scale,
) <-- keepalive 시간이 지날 때 마다 autoscaler.maybe_scale 이 호출되도록 설정 (timer)
# (아래 kombu 코드 참고)
class Autoscaler(bgThread): <-- 아래 bgThread 코드 참고
"""Background thread to autoscale pool workers."""
...
def body(self):
with self.mutex:
self.maybe_scale()
sleep(1.0)# kombu/asynchronous/hub.py
class Hub:
"""Event loop object.
Arguments:
---------
timer (kombu.asynchronous.Timer): Specify custom timer instance.
"""
...
def call_repeatedly(self, delay, callback, *args):
return self.timer.call_repeatedly(delay, callback, args)# kombu/asynchronous/timer.py
class Timer:
"""Async timer implementation."""
...
def call_repeatedly(self, secs, fun, args=(), kwargs=None, priority=0):
kwargs = {} if not kwargs else kwargs
tref = self.Entry(fun, args, kwargs)
@wraps(fun)
def _reschedules(*args, **kwargs):
last, now = tref._last_run, monotonic()
lsince = (now - tref._last_run) if last else secs
try:
if lsince and lsince >= secs:
tref._last_run = now
return fun(*args, **kwargs)
finally:
if not tref.canceled:
last = tref._last_run
next = secs - (now - last) if last else secs
self.enter_after(next, tref, priority)
tref.fun = _reschedules
tref._last_run = None
return self.enter_after(secs, tref, priority)
# self.enter_after: secs가 지나면 scheduler (timer)에 tref 를 Enter
# secs = 30 초 (AUTOSCALE_KEEPALIVE)# celery/utils/threads.py
class bgThread(threading.Thread):
"""Background service thread."""
...
def run(self):
body = self.body
shutdown_set = self.__is_shutdown.is_set
try:
while not shutdown_set(): <-- shutdown 될 때까지 loop
try:
body()
except Exception as exc: # pylint: disable=broad-except
try:
self.on_crash('{0!r} crashed: {1!r}', self.name, exc)
self._set_stopped()
finally:
sys.stderr.flush()
os._exit(1) # exiting by normal means won't work
finally:
self._set_stopped()
위 코드들을 종합해봤을 때, 총 세 가지 case 때 scaling 을 시도한다.
- task 를 receive 했을 때 (WorkerComponent > register_with_event_loop 메서드 참고)
- keepalive (default: 30초) 간격으로 (WorkerComponent > register_with_event_loop 메서드 참고)
- Autoscaler 의 body 메서드가 호출 될 때. 즉, 1초 간격으로
Maintain Pool
이전 섹션에서 확인할 수 있듯이, autoscaler는 maybe_scale 메서드 실행 중 실제로 scaling이 진행되었다면 그 다음으로 self.pool.maintain_pool() 로직을 수행한다. scale down 시 WorkerChildProcess terminate (exit) 만 진행하고 해당 process를 pool 에서 join (cleanup) 하지는 않는다. 그러므로 maintain_pool 을 통해 pool 정리 (join exited worker & repopulate pool) 를 추가로 해주어야 하는 것이다.
# billiard/pool.py
...
class Pool:
'''
Class which supports an async version of applying functions to arguments.
'''
...
def _maintain_pool(self):
""""Clean up any exited workers and start replacements for them.
"""
joined = self._join_exited_workers()
self._repopulate_pool(joined)
for i in range(len(joined)):
if self._putlock is not None:
self._putlock.release()
def maintain_pool(self):
if self._worker_handler._state == RUN and self._state == RUN:
try:
self._maintain_pool()
except RestartFreqExceeded:
self.close()
self.join()
raise
except OSError as exc:
if get_errno(exc) == errno.ENOMEM:
raise MemoryError from exc
raise
...
def _join_exited_workers(self, shutdown=False):
"""Cleanup after any worker processes which have exited due to
reaching their specified lifetime. Returns True if any workers were
cleaned up.
"""
now = None
# The worker may have published a result before being terminated,
# but we have no way to accurately tell if it did. So we wait for
# _lost_worker_timeout seconds before we mark the job with
# WorkerLostError.
for job in [job for job in list(self._cache.values())
if not job.ready() and job._worker_lost]:
now = now or monotonic()
lost_time, lost_ret = job._worker_lost
if now - lost_time > job._lost_worker_timeout:
self.mark_as_worker_lost(job, lost_ret)
if shutdown and not len(self._pool):
raise WorkersJoined()
cleaned, exitcodes = {}, {}
for i in reversed(range(len(self._pool))):
worker = self._pool[i]
exitcode = worker.exitcode
popen = worker._popen
if popen is None or exitcode is not None:
# worker exited
debug('Supervisor: cleaning up worker %d', i)
if popen is not None:
worker.join()
debug('Supervisor: worked %d joined', i)
cleaned[worker.pid] = worker
exitcodes[worker.pid] = exitcode
if exitcode not in (EX_OK, EX_RECYCLE) and \
not getattr(worker, '_controlled_termination', False):
error(
'Process %r pid:%r exited with %r',
worker.name, worker.pid, human_status(exitcode),
exc_info=0,
)
self.process_flush_queues(worker)
del self._pool[i]
del self._poolctrl[worker.pid]
del self._on_ready_counters[worker.pid]
if cleaned:
all_pids = [w.pid for w in self._pool]
for job in list(self._cache.values()):
acked_by_gone = next(
(pid for pid in job.worker_pids()
if pid in cleaned or pid not in all_pids),
None
)
# already accepted by process
if acked_by_gone:
self.on_job_process_down(job, acked_by_gone)
if not job.ready():
exitcode = exitcodes.get(acked_by_gone) or 0
proc = cleaned.get(acked_by_gone)
if proc and getattr(proc, '_job_terminated', False):
job._set_terminated(exitcode)
else:
self.on_job_process_lost(
job, acked_by_gone, exitcode,
)
else:
# started writing to
write_to = job._write_to
# was scheduled to write to
sched_for = job._scheduled_for
if write_to and not write_to._is_alive():
self.on_job_process_down(job, write_to.pid)
elif sched_for and not sched_for._is_alive():
self.on_job_process_down(job, sched_for.pid)
for worker in cleaned.values():
if self.on_process_down:
if not shutdown:
self._process_cleanup_queues(worker)
self.on_process_down(worker)
return list(exitcodes.values())
return []
...
def mark_as_worker_lost(self, job, exitcode):
try:
raise WorkerLostError(
'Worker exited prematurely: {0} Job: {1}.'.format(
human_status(exitcode), job._job),
)
except WorkerLostError:
job._set(None, (False, ExceptionInfo()))
else: # pragma: no cover
pass# celery/concurrency/asynpool.py
class AsynPool(_pool.Pool): <-- billiard 의 Pool을 상속
"""AsyncIO Pool (no threads)."""
...
def on_job_process_lost(self, job, pid, exitcode):
"""Called when the process executing job' exits.
This happens when the process job'
was assigned to exited by mysterious means (error exitcodes and
signals).
"""
self.mark_as_worker_lost(job, exitcode)
maintain_pool 메서드 부터 따라가며 코드 내용을 종합해보면 다음과 같다:
- _join_exited_workers 메서드 호출
- autoscale 로 인해서 acked_by_gone (특정 job 이 exit 된 worker 에 할당되어 있는 경우 = Orphan job) 상황 발생
- on_job_process_lost 메서드 호출
- mark_as_worker_lost 메서드 호출
- Orphan job 에 대해 WorkerLostError 발생
이 부분에서, 처음에 가정했던 'Scale-down 대상인 WorkerChildProcess 에 Task 가 할당되면서 타이밍 이슈 (acked by gone)로 WorkerLostError가 발생' 하는 것을 확실히 알 수 있다.
Conclusion
Summary
지금까지 이 글에서는 특정 패턴의 MWAA 장애 원인에 대해 심층적으로 분석해보았다. 해당 장애는 Celery 상에서 발생하는 WorkerLostError 가 원인이었고 Celery Worker 의 autoscaling 기능 으로 인해 발생하는 에러였다. 이는 다음 근거들을 통해 뒷받침 되었다:
- AWS 측 답변
- Airflow Worker Log 심층 분석 및 관련 이슈 구글링
- Celery 소스코드 분석
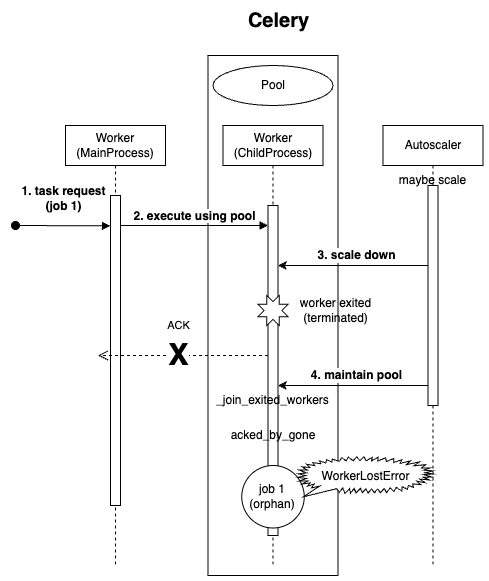
위 그림은 여태까지 논의된 내용을 총 망라한 WorkerLostError Sequence Diagram이다. 주요 흐름을 요약하자면 다음과 같다:
- 1. Worker MainProcess 에서 job1 (task) 에 대한 request 를 받는다
- 2. TaskPool 에 job1 에 대한 execution 을 위임 → Worker ChildProcess 에게 job1 할당
- 3. Worker ChildProcess 가 job1 을 받은 것에 대한 ACK 를 MainProcess 로 보내기 전에 Autoscaler가 개입 → scale down → WorkerChildProcess exited (terminated)
- 4. maintain pool → job1 이 3번 과정에서 exited (terminated) 된 WorkerChildProcess 에 귀속되어 있으므로 acked_by_gone 상황 발생 (orphan job) → job1 (orphan job) 에 대해 WorkerLostError 발생
Solution
해결책은 허무하게도 아주 간단하다. Celery Autoscale 을 사용하지 않는 것. 여러 Celery 이슈 글에서도 이를 권고하고 있고, 심지어 잘 찾아보니 AWS 측에서도 공식 docs 상에서 이를 권고하고 있었다 (아주 꽁꽁 숨겨놨다. 그리고 왜 Case Open 때 언급도 없었던 건지 참...). 아무튼 꼭 celery 의 auto-scale 기능이 필요한 것이 아니라면, 해당 기능은 끄는게 best practice 로 확인된다. 참고로 Celery 개발 팀 측에서는 리소스 부족으로 이에 대한 해결을 미루고 있는 듯 하다. auto-scale 기능 off 방법은 celery.worker_autoscale 설정의 max, min pool size 를 동일하게 설정해두면 된다.
# 예시
celery.worker_autoscale 5,5
'개발 > 트러블슈팅' 카테고리의 다른 글
| [pyspark] TypeError: Column is not iterable 에러 트러블 슈팅 (0) | 2023.05.12 |
|---|